
o3: Stratospheric reasoning – Dr Alan D. Thompson – LifeArchitect.ai
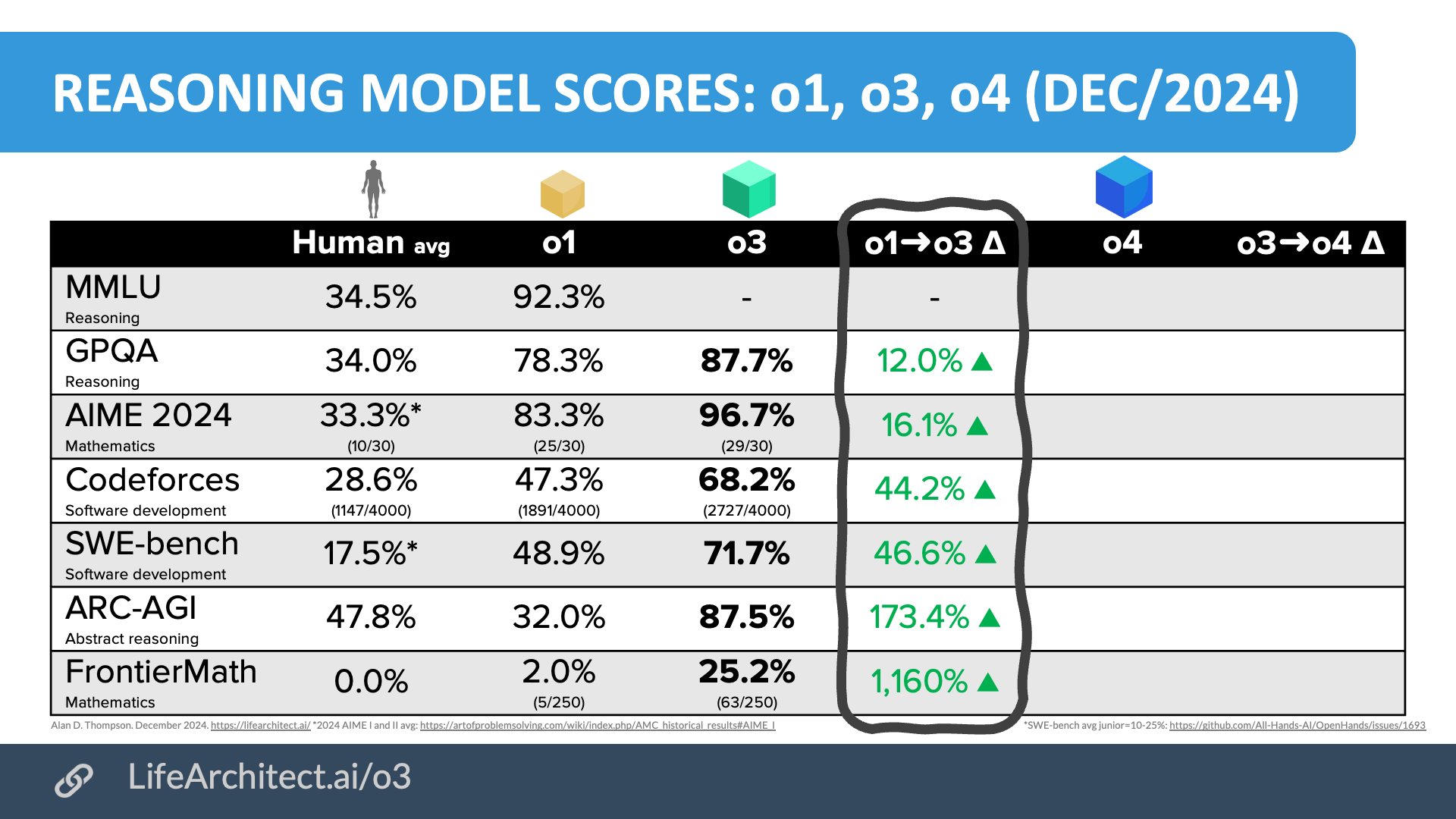
“I haven’t seen o3 yet & have been critical of benchmarks for AI but they did test against some of the hardest & best ones On GPQA, PhDs with access to the internet got 34% outside their specialty, up to 81% inside. o3 is 87%. Frontier Math went from the best AI at 2% to 25%
https://x.com/emollick/status/1870354095011213722
“LLMs evolve cooperative behaviors through multi-generational learning in simulated economic games. Like human, some AI models naturally develop teamwork skills, while others become lone wolves. This research examines how LLM agents develop cooperative behaviors over multiple
https://x.com/rohanpaul_ai/status/1870935564729635320
“o3 can solve 25% of research level mathematics questions designed by experts out of the box It’s literally over lmao
https://x.com/nim_chimpsky_/status/1870170283891421690
“Interesting new research from @AIatMeta on exploring better reasoning using latent space instead of output tokens. “Coconut” (Chain of Continuous Thought) enables more efficient and effective reasoning, particularly for complex planning tasks. In Coconut, the LLM has two modes.
https://x.com/_philschmid/status/1871117240176894247
“New verified ARC-AGI-Pub SoTA! @OpenAI o3 has scored a breakthrough 75.7% on the ARC-AGI Semi-Private Evaluation. And a high-compute o3 configuration (not eligible for ARC-AGI-Pub) scored 87.5% on the Semi-Private Eval. 1/4
https://x.com/arcprize/status/1870169260850573333
“OpenAI’s o3 is absolutely incredible, and I am so excited about it, but its nowhere near to AGI. “early data points suggest that the upcoming ARC-AGI-2 benchmark will still pose a significant challenge to o3, potentially reducing its score to under 30% even at high compute
https://x.com/rohanpaul_ai/status/1870575885696598152
“Independent evaluations of OpenAI’s o3 suggest that it passed benchmarks that were previously considered far out of reach for AI including achieving a score on ARC-AGI that was associated with actually achieving AGI (though the creators of the benchmark don’t think it o3 is AGI)” / X
https://x.com/emollick/status/1870172935064818045
“OpenAI announced ‘o3’, the next iteration of o1 that surpasses it across all benchmarks Pretty incredible to see o3 topping 85% on the ARC-AGI benchmark It’s currently only available in preview to safety and security researchers
https://x.com/adcock_brett/status/1870877753081217359
“🧭 As o3 tackles ARC-AGI’s Semi-Private Evaluation, here’s what this benchmark is about: Created by @fchollet, it tests AI’s ability to solve puzzles it’s never seen before—using only basic human priors like geometry & counting. It strips away language & cultural knowledge.
https://x.com/fdaudens/status/1870539776610472002
“imo the improvements on FrontierMath are even more impressive than ARG-AGI. Jump from 2% to 25% Terence Tao said the dataset should “resist AIs for several years at least” and “These are extremely challenging. I think that in the near term basically the only way to solve them,” / X
https://x.com/dmdohan/status/1870176374625054880
“@DavidSHolz Think most benchmarks are necessary not sufficient Beating ARC-AGI doesn’t mean you actually have AGI, but it would be surprising to have an AGI that couldn’t do it. Though FrontierMath is hard enough that we could have an AGI that doesn’t solve it, not sure here.” / X
https://x.com/dmdohan/status/1870182433020314004
“Today OpenAI announced o3, its next-gen reasoning model. We’ve worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tasks. It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task
https://x.com/fchollet/status/1870169764762710376
[AINews] o3 solves AIME, GPQA, Codeforces, makes 11 years of progress in ARC-AGI and 25% in FrontierMath • Buttondown
https://buttondown.com/ainews/archive/ainews-o3-solves-aime-gpqa-codeforces-makes-11/
“🌌 Open-source spirit + Longtermism to inclusive AGI 🌟 DeepSeek’s mission is unwavering. We’re thrilled to share our progress with the community and see the gap between open and closed models narrowing. 🚀 This is just the beginning! Look forward to multimodal support and” / X
https://x.com/deepseek_ai/status/1872242666265801105
“AGI is a misused and overrated term. We only need narrow scientific superintelligence and o1 models are well on their way of becoming exactly that. This narrow scientific superintelligence will help us build AGI.
https://x.com/scaling01/status/1871058354795352508
“AGI is going to prove a limited standard to think about because we will have Jagged AGI – superhuman at some tasks, weaker at others. Just because it is as good as the 175th best competitive coder on Earth doesn’t mean that it is as good as them at every task they do (for now)” / X
https://x.com/emollick/status/1870183565406654616
“I’m excited to see more initiatives to make mechanistic interpretability and sparse autoencoder research easier on large models! Seems like cool work” / X
https://x.com/NeelNanda5/status/1871248918635557260
“NEW: OpenAI just announced ‘o3’, a breakthrough AI model that significantly surpasses all previous models in benchmarks. —On ARC-AGI: o3 more than triples o1’s score on low compute and surpasses a score of 87% —On EpochAI’s Frontier Math: o3 set a new record, solving 25.2% of
https://x.com/rowancheung/status/1870169402248945822
“ARC-AGI scores for past five years of OpenAI models (updated w/ release dates)
https://x.com/goodside/status/1870243391814152544
OpenAI o3 Breakthrough High Score on ARC-AGI-Pub
https://arcprize.org/blog/oai-o3-pub-breakthrough
“New verified ARC-AGI-Pub SoTA! @OpenAI o3 has scored a breakthrough 75.7% on the ARC-AGI Semi-Private Evaluation. And a high-compute o3 configuration (not eligible for ARC-AGI-Pub) scored 87.5% on the Semi-Private Eval. 1/4
https://x.com/arcprize/status/1870169260850573333
Scaling Laws – O1 Pro Architecture, Reasoning Training Infrastructure, Orion and Claude 3.5 Opus “Failures” – SemiAnalysis
(2) o3: The grand finale of AI in 2024 – by Nathan Lambert
https://www.interconnects.ai/p/openais-o3-the-2024-finale-of-ai
[2412.16145] Offline Reinforcement Learning for LLM Multi-Step Reasoning
https://arxiv.org/abs/2412.16145
[AINews] FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI • Buttondown
https://buttondown.com/ainews/archive/ainews-frontiermath-a-benchmark-for-evaluating/
“Transformers learn by mapping concepts to unique mental spaces, create distinct mental neighborhoods for different concepts just like humans organize thoughts. This paper reveals how transformers learn in-context learning through a concept encoding-decoding mechanism, explaining”
https://x.com/rohanpaul_ai/status/1871797175715611003
“Teaching LLMs human preferences just got faster by mixing past knowledge with active learning. HPO combines offline preference datasets with online exploration for more efficient RLHF training, achieving faster convergence by leveraging existing data while exploring new”
https://x.com/rohanpaul_ai/status/1872028317605576944




{kind=link}